Nginx 线上 502、504,到底该查哪一层?
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
2、Nginx 接口没报错,用户却投诉打不开?这个码叫 499 01 | 线上 502、504,到底该查哪一层?
凌晨两点,告警群炸了。某个核心接口大面积报错,用户截图甩过来——浏览器一个大大的 502。 你登上去,面对的是 Nginx + 后端这套烂熟、却最容易把人绕晕的链路:到底是 Nginx 的锅,还是后端挂了,还是机器本身不行了? 排障最怕的不是没命令,是没方向——十个命令敲下去,十分钟后还在原地打转。 这篇就把 502/504 这条最常踩的线,从定位到恢复,一次性讲透。后面几篇会接着拆 499、503、OOM。 一、先搞清楚:这个码,是哪一层报的?很多人排查一上来就翻日志,翻半天找不到方向。其实状态码本身就是路标——它告诉你故障发生在链路的哪一段。 先记住下面这张图,后面所有排查都围着它转: 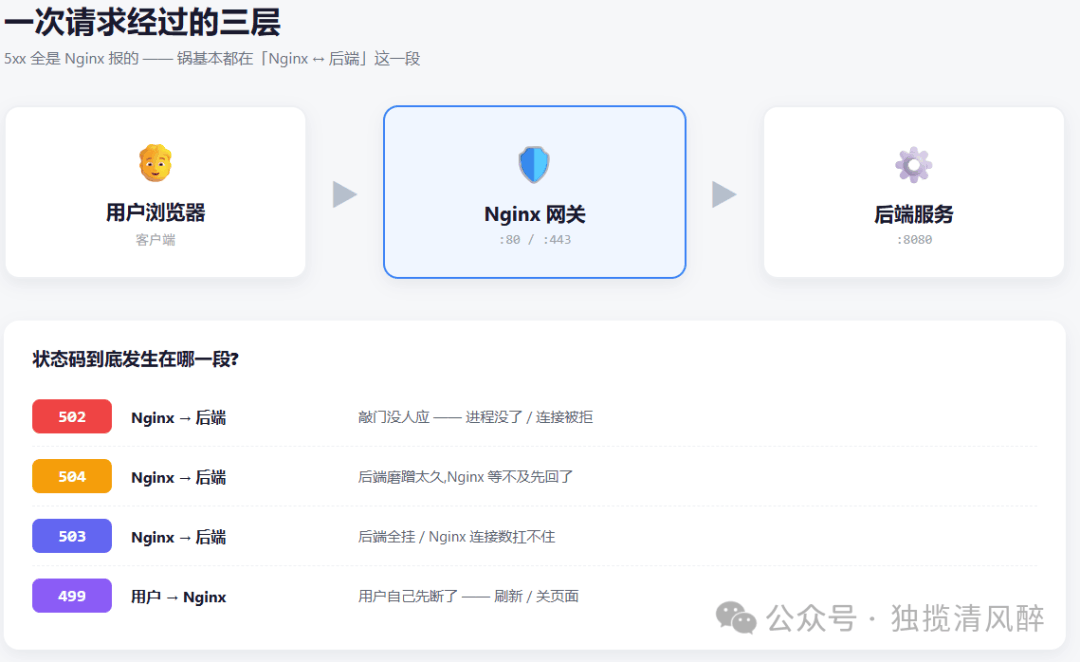 一句话总结这四个码的"出身":
注意一个关键点:这四个码全是 Nginx 报的。也就是说,当你看到 5xx,问题基本都出在 "Nginx ↔ 后端" 这一段,或者 Nginx 自己。前端、CDN、用户网络这些环节,99% 的情况下不用最先怀疑。 记住这张图,你的排查范围立刻砍掉一半。 二、最值钱的一招:curl 直连后端,10 秒切两半排 502 我见过最多的弯路:一上来翻 Nginx 配置、翻后端日志、翻机器资源,三个地方一起看,信息量爆炸,反而定不了位。 其实有个动作能让你十秒钟把故障切成两半——绕过 Nginx,直接 curl 后端端口。 先看 Nginx 的 upstream 配的是谁: 拿到后端地址(比如 这一步本质上是在做二分——把链路从 Nginx 处一刀切开:
后端通 → 别在后端死磕了,回头查 Nginx;后端也挂 → 别在 Nginx 浪费时间,直接扎进应用和资源。 就这么简单的一刀,能省你一半的排查时间。记住它。 三、Nginx 错误日志:别整段看,只盯三个关键词
再留意日志里的 四、排查决策树:照着走,不跑偏把前面几步串成一张决策图。打印出来贴工位上,告警一来照着走就行:  这张图的核心逻辑就一句话:先用 curl 把层级切开,再按层级往里钻。不要跳步,不要并行乱看。 五、两个最隐蔽的坑,踩过才记得住常规排查讲完,说两个我反复见人栽跟头的地方。 坑一:proxy_read_timeout 被 location 悄悄覆盖线上某个报表接口疯狂 504。你去看全局配置, 结果发现某个 教训:Nginx 超时配置别只看主配置,要 grep 全目录。临时解法是给慢接口单独放宽: 但这只是止痛药。真正该做的是回头优化这个慢接口,否则迟早被流量教做人。 坑二:后端被 OOM 干掉,应用日志一个字都不写最阴的一种 502:后端进程"莫名其妙"没了,应用日志干干净净,没有任何报错堆栈。你翻半天日志啥也翻不出来。 这时候别看应用日志,去看内核日志: 如果看到 这个坑的恶心之处在于:只看应用日志永远查不出来。养成习惯,排 502 没头绪时,顺手 六、先恢复,后排查:应急三板斧定位归定位,但凌晨两点,领导只关心一件事——多久能恢复。 记住原则:先恢复业务,再慢慢查根因。别在用户还在掉单的时候,你还在那优雅地分析日志。 三招按场景挑:
摘节点的小技巧——给故障节点加 七、复盘清单:这次查完,别让它再发生故障恢复不是结束。对照下面这张表,给每个根因配一个长期措施,不然下次凌晨两点还得爬起来: 最后那条尤其重要——与其等告警,不如让监控提前喊你。Nginx upstream 的响应时间、5xx 数量突增、后端进程的 CPU/内存,这几个指标配好告警,很多故障在你睡觉的时候就能自动兜住。 写在最后这篇的核心其实就三句话:
下一篇 02,讲那个最容易被忽视的码——499。明明你的接口一个错都没报,用户却疯狂投诉"打不开""转圈圈",问题到底出在哪。
阅读原文:点击这里 该文章在 2026/6/23 9:31:20 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886


